OmniGen:通过自然语言生成/编辑/合成图像
功能介绍
OmniGen 核心能力是通过自然语言来进行图像生成/图像编辑以及图像合成,而不再需要手动的去使用传统的 controlNet,IPAdaptor 和遮罩控制等能力,将生图和编辑图像变的简单。
包含能力:
- 文生图
- 局部重绘
- 骨架图抽取
- 根据骨架图生成图片
- 图生图
- 多图合成

安装应用
系统要求:需要 GPU 支持,且显存大小需要 8G 以上。 下面以 Windows11 为例,演示安装流程,在 cmd 中依次输入以下命令
shell
cd D:\ai\self_use_package
conda create -n omnigen python=3.10.13
conda activate omnigen
# Install pytorch with your CUDA version, e.g.
pip install torch==2.3.1+cu118 torchvision --extra-index-url https://download.pytorch.org/whl/cu118
git clone https://github.com/VectorSpaceLab/OmniGen.git
cd OmniGen
pip install -e .
pip install gradio spaces启动应用
在 cmd 中输入以下命令
shell
python app.py在 cmd 中看到如下日志,表示成功(首次启动会从 HuggingFace 上拉取模型)
shell
Model not found, downloading...
Fetching 10 files: 100%|███████████████████████████████████████████████████████████████████████| 10/10 [00:00<?, ?it/s]
Downloaded model to D:\ai\self_use_package\OmniGen\huggingface\hub\models--Shitao--OmniGen-v1\snapshots\58e249c7c7634423c0ba41c34a774af79aa87889
Loading safetensors
* Running on local URL: http://127.0.0.1:7860此时浏览器输入 http://127.0.0.1:7860,展示界面如下(界面包含:参数说明/操作区/示例区,以下仅贴出操作区)
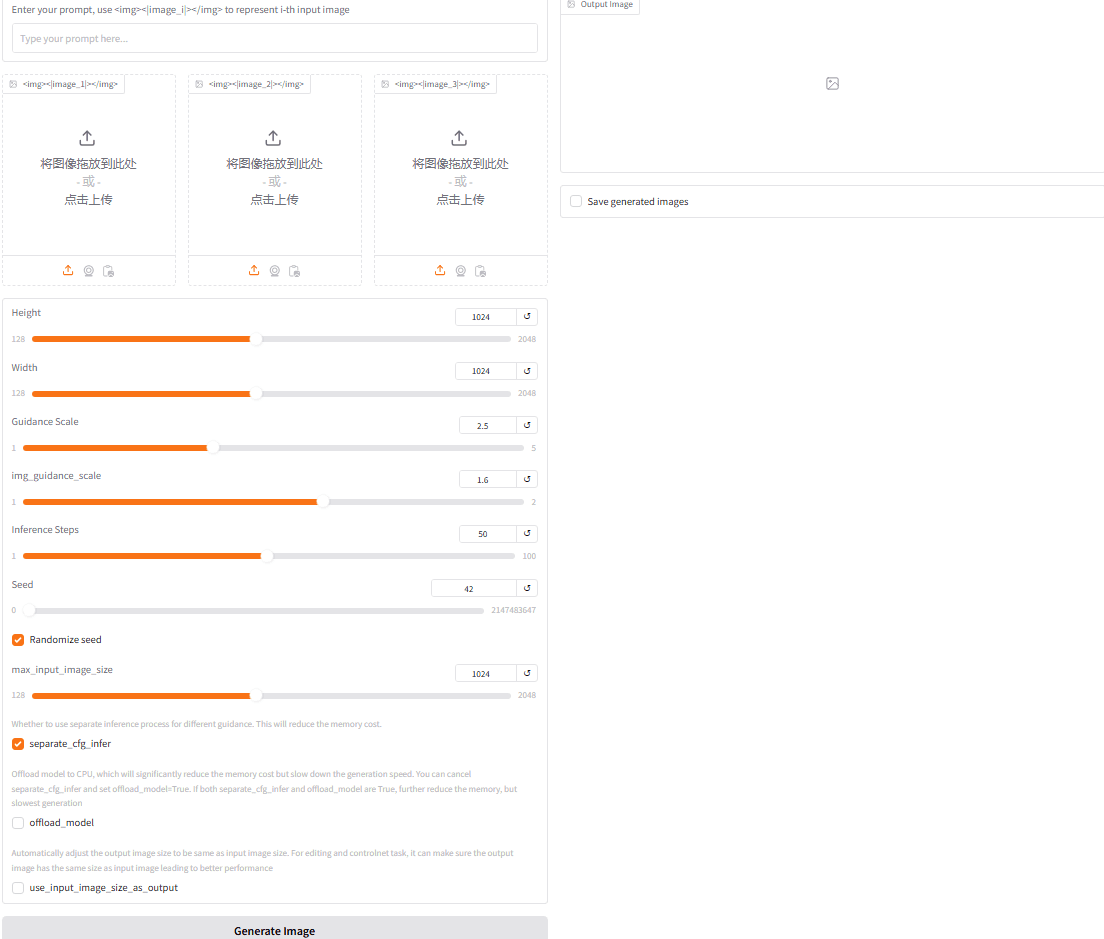
重要参数:
- guidance_scale: The strength of the guidance. Based on our experience, it is usually best to set it between
2 and 3. The higher the value, the more similar the generated image will be to the prompt. If the image appears oversaturated, please reduce the scale. - height and width: The height and width of the generated image. The default value is 1024x1024. OmniGen support any size, but
these number must be divisible by 16. - num_inference_steps: The number of steps to take in the diffusion process. The higher the value, the more detailed the generated image will be.
- max_input_image_size: the maximum size of input image,
which will be used to crop the input image to the maximum size. A smaller number will result in faster generation speed and lower memory cost. - offload_model: offload the model to cpu, which can save memory but slow down the generation. Default is False.
- use_input_image_size_as_output: whether to use the input image size as the output image size, which can be used for single-image input, e.g., image editing task. Default is False.
- seed: The seed for random number generator.
官方建议:
- For image editing task and controlnet task, we recommend setting the height and width of output image as the same as input image. For example, if you want to edit a 512x512 image, you should set the height and width of output image as 512x512. You also can set the use_input_image_size_as_output to automatically set the height and width of output image as the same as input image.
- For out-of-memory or time cost, you can set
offload_model=True. - If inference time is too long when inputting multiple images, please try to
reduce the max_input_image_size. - Oversaturated: If the image appears oversaturated, please
reduce the guidance_scale. - Not matching the prompt: If the image does not match the prompt, please try to
increase the guidance_scale. - Low-quality: A
more detailed promptwill lead to better results. - Animated Style: If you want the generated image to appear less animated, and more realistic, you can try adding
phototo the prompt. - Editing generated images: If you generate an image with OmniGen, and then want to edit it, you cannot use the same seed to edit this image. For example, use seed=0 to generate the image, and then use seed=1 to edit this image.
- For multi-modal to image generation, you should pass a string as prompt, and a list of image paths as input_images. The placeholder in the prompt should be in the format of
<img><|image_*|></img>(for the first image, the placeholder is<|image_1|>. for the second image, the placeholder is<|image_2|>). For example, use an image of a woman to generate a new image: prompt = "A woman holds a bouquet of flowers and faces the camera. The woman is<|image_1|>."
- Image editing: In your prompt, we recommend placing the image before the editing instructions. For example, use
<img><|image_1|></img> remove suit, rather than remove suit<|image_1|>.
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
