IndexTTS1.5:最简最逼真的开源的语音克隆/TTS工具
功能介绍
IndexTTS 核心能力是 TTS(TextToSpeech),如下所示,上传一段参考音频和文本,可以使用该音频的音色阅读该文本。 其对复杂文字的阅读流畅度(比如,需要阅读的文字包含数字/英文/中文)和克隆声音的逼真度要超过 CosyVoice2;且使用简单,不再需要像 CosyVoice2 一样上传音频的同时,还要上传音频的文字内容来保障克隆效果。 且整合包体积仅有 9.6G,CosyVoice2 的全模型版本需要 33.3G。目前 IndexTTS 缺乏情感控制,且功能的齐全性方面要差于 CosyVoice2。
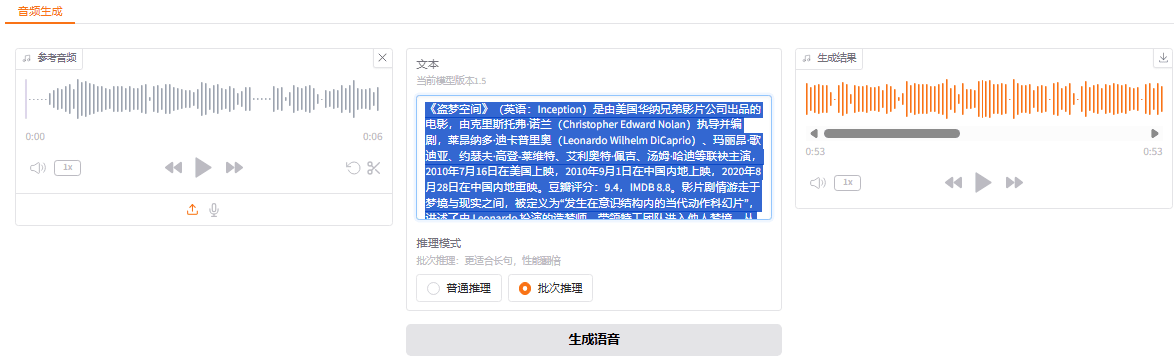
安装应用
显存要求:8G(下面的测试例子仅用了 6.1G)
下面以 Windows11 为例,演示安装流程。在 cmd 中依次输入以下命令
shell
git clone https://github.com/index-tts/index-tts.git
cd index-tts
conda create -n index-tts python=3.10 -y
conda activate index-tts
# 注释掉 requirements.txt 中的 WeTextProcessing 和 wetext
pip install -r requirements.txt
conda install -c conda-forge pynini==2.1.5
pip install WeTextProcessing==1.0.3
pip install -e ".[webui]"
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
# 下载模型
huggingface-cli download IndexTeam/IndexTTS-1.5 config.yaml bigvgan_discriminator.pth bigvgan_generator.pth bpe.model dvae.pth gpt.pth unigram_12000.vocab --local-dir checkpoints
# 启动应用
python webui.py使用
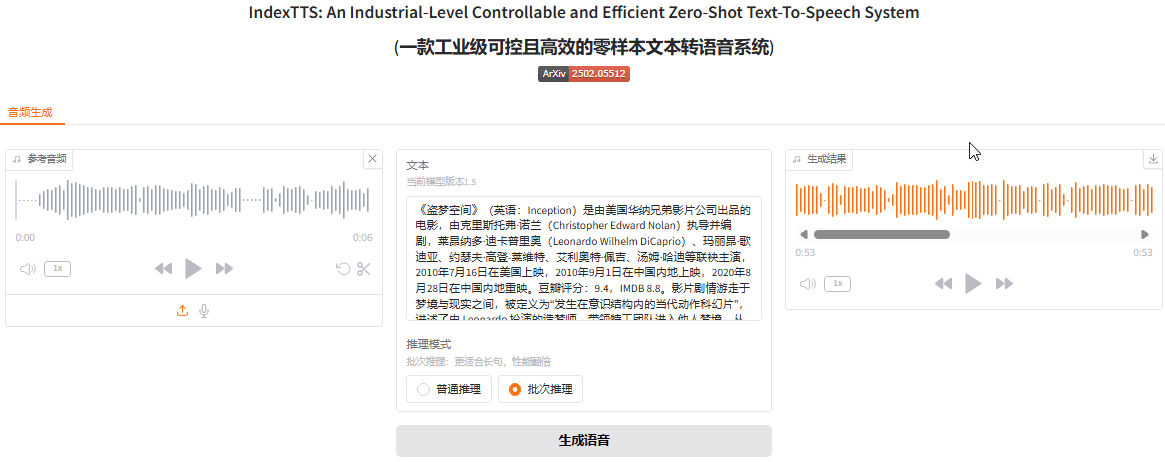
如上所示,上述的文字包含数字/英文/中文,IndexTTS 也可以非常好的进行 tts 处理。
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
