强大易用低显存高速开源放大神器 HYPIR
功能介绍
图片高清化,效果如下: 
显存占用情况:
- 将一张 831*676 的图片按照原倍数高清化,仅需 6G 显存
- 将一张 831676 的图片放大2倍到 16621352,仅需 6.4G 显存
安装
安装环境
shell
conda create -n hypir_env python=3.10 -y
conda activate hypir_env
git clone https://github.com/XPixelGroup/HYPIR.git
cd HYPIR
pip install -r requirements.txt
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126下载模型
下载放大模型 HYPIR_sd2.pth,放置到 HYPIR\models\ 下(如果没有 models 目录,则新建)。
之后修改配置文件 HYPIR\configs\sd2_gradio.yaml 中的 weight_path 路径(其他保持不变),内容如下:
shell
base_model_type: sd2
base_model_path: stabilityai/stable-diffusion-2-1-base
model_t: 200
coeff_t: 200
lora_rank: 256
lora_modules: [to_k, to_q, to_v, to_out.0, conv, conv1, conv2, conv_shortcut, conv_out, proj_in, proj_out, ff.net.2, ff.net.0.proj]
weight_path: models/HYPIR_sd2.pth启动应用
shell
python app.py --config configs/sd2_gradio.yaml --local --device cuda看到如下输出,表示成功:
text
Load model weights from models/HYPIR_sd2.pth
* Running on local URL: http://127.0.0.1:7860浏览器输入 http://127.0.0.1:7860,操作界面如下:
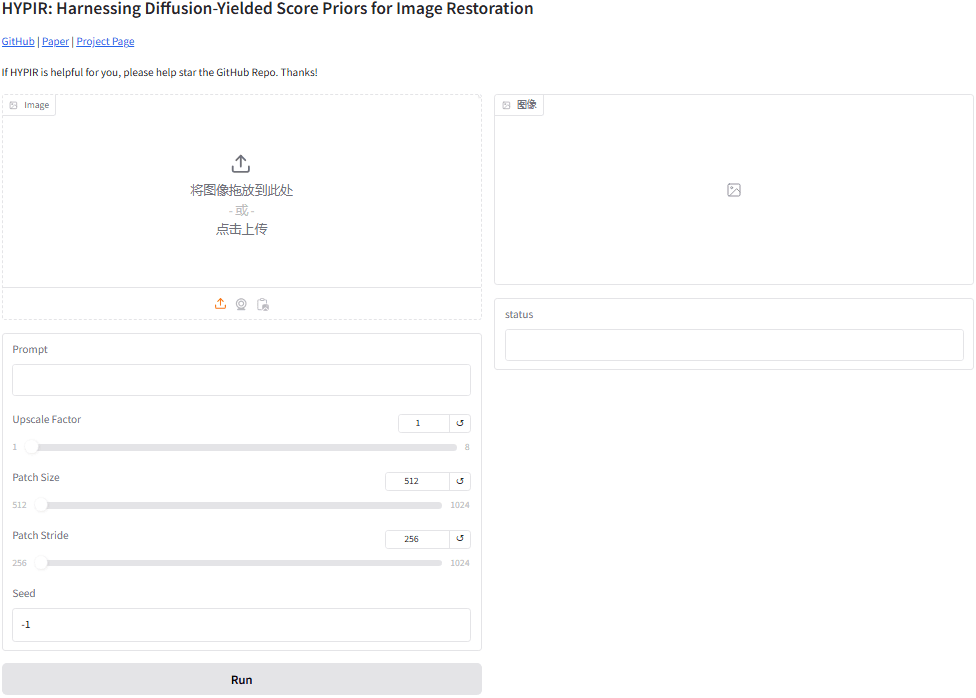
开始使用
上传待高清化的图片 => 调整参数 => 点击“Run”进行高清化
核心参数如下
- Prompt:提示语,可以使用最简单的描述,例如“1man”,也可以通过 JoyCaption2 去反推
- Upscale Factor:图片放大倍数
- Patch Size:默认512,当发现部分区块处理效果不佳时,可以调大该值。增大patch_size可以让模型看见更大的区域,因此可以提高consistency。代价就是会消耗更多的显存。
- Patch Stride:默认为256,如果发现整个图有
区块裂缝,减小该值;减小patch_stride可以让patch之间的overlap变大,因此可以提高相邻patch之间的consistency。
关于 Patch Size 与 Patch Stride 的解释:
text
为了处理任意大小的输入,一个常见的做法是把输入切分成多个具有一定重叠的子patch,模型依次处理每一个patch,最后进行融合。
patch_size决定了每个patch的大小,patch_stride决定了每个patch之间的距离,显然,patch_overlap = patch_size - patch_stride。
增大patch_size可以让模型看见更大的区域,因此可以提高consistency。代价就是会消耗更多的显存。
减小patch_stride可以让patch之间的overlap变大,因此可以提高相邻patch之间的consistency。如果高清化后的图片太锐利,可以修改提示词,同时开源模型对于 1024 以上的模型的放大效果更好。具体的解释见该 issue:
text
This model is sensitive to the give prompt, so you'd better provide prompt through GPT or Gemini. For auto-captioning, the current code only supports using GPT within Gradio.
I find that the open-sourced model performs better at resolution > 1024, while artifacts and unnatural style will appear in smaller resolution. This seems to be a training issue, and perhaps a more natural-looking model will be trained later (I probably won't be free for the next month or two).文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
