多模态大模型最新王者 Qwen3-VL
Qwen3-VL 模型种类
MOE 模型
- Qwen3-VL-235B-A22B-Instruct:非思考模型中的旗舰模型
- Qwen3-VL-235B-A22B-Thinking:思考模型中的旗舰模型
- Qwen3-VL-30B-A3B-Instruct
- Qwen3-VL-30B-A3B-Thinking
稠密模型
- Qwen3-VL-8B-Instruct
- Qwen3-VL-8B-Thinking
- Qwen3-VL-4B-Instruct
- Qwen3-VL-4B-Thinking
本地 24G 显存可以部署的最优模型是 Qwen3-VL-8B-Thinking。
核心亮点
- 视觉编码增强:从图像/视频生成 Draw.io/HTML/CSS/JS
- 高级空间感知:判断物体位置、视角和遮挡
- 长上下文和视频理解:原生 256K 上下文,可扩展到 1M;处理书籍和数小时的视频
- 增强的多模态推理:在 STEM/数学方面表现出色 —— 因果分析和基于逻辑、证据的答案
- 升级的视觉识别:更广泛、更高品质的预训练能够“识别一切” —— 名人、动漫、产品、地标、动植物等
- 扩展的 OCR:支持 32 种语言;在低光、模糊和倾斜情况下表现稳健;更好地处理罕见/古代字符和术语;改进了长文档结构解析
- 与纯 LLM 相当的文本理解:无缝的文本-视觉融合,实现无损、统一的理解
安装软件
由于安装相对麻烦,故制作了一键整合包,关注本公众号,回复 qwen3vl 获取。安装包仅提供了软件代码和环境依赖,模型文件可以自行去如下提供的 modelscope 地址下载。所以如果是24G显存,可以下载 8B 模型,如果显存不足,可以尝试 4B 模型。
shell
conda create -n qwen3_vl_env python=3.12 -y
conda activate qwen3_vl_env
git clone https://github.com/QwenLM/Qwen3-VL.git
cd Qwen3-VL修改 requirements_web_demo.txt 文件如下(否则会有兼容性问题):
shell
gradio==5.46.1
gradio_client==1.13.1
transformers-stream-generator==0.0.5
transformers==4.57.0
accelerate继续安装依赖
shell
pip install -r requirements_web_demo.txt
pip uninstall torch
pip install torch torchvision --index-url https://download.pytorch.org/whl/cu126在项目根目录 Qwen3-VL 下新建文件夹 model,用于存储模型文件。从 这里 下载全部文件到 model 文件夹中。
运行软件
shell
python web_demo_mm.py -c model/ --backend hf核心启动参数如下:
- -c:模型文件地址
- --backend:可选项 hf 和 vllm。windows 只能用 hf,不支持 vllm
- --flash-attn2:打开推理加速,默认false
- --cpu-only:仅使用 cpu 运行
- 其他host/port/浏览器自动开启等参数不再赘述,感兴趣的可以查看
web_demo_mm.py文件中的代码
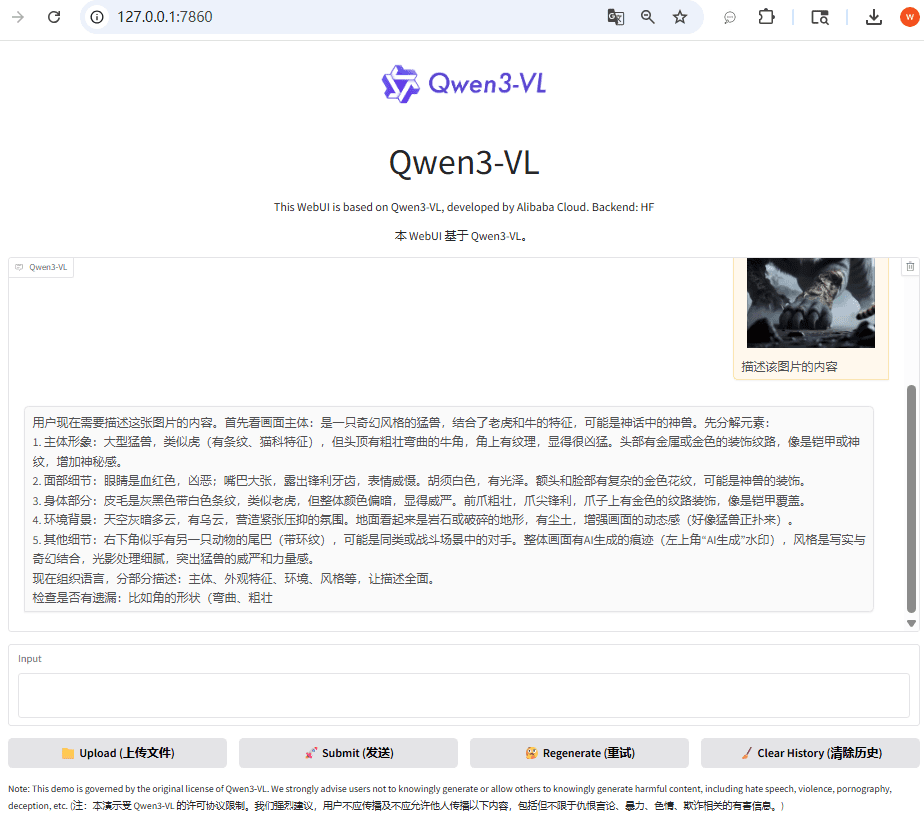
启动之后,打开 UI 界面,上传文件,输入文本,发送即可
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
