安装全模态模型 Qwen2.5-Omni
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。
核心功能:
- 支持音视频实时交互:通过麦克风和摄像头传递音视频指令给模型,模型返回响应
- 支持上传图片/音频/视频/文字指令
使用场景演示见 视频
安装
shell
# 克隆项目
git clone https://github.com/QwenLM/Qwen2.5-Omni.git
cd Qwen2.5-Omni
# 创建虚拟环境
conda create -n qwen_omni_env python=3.12 -y
conda activate qwen_omni_env
# 安装依赖
pip install -r requirements_web_demo.txt
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
# 安装 flash-attention2 和 triton(可选)
# https://www.aileading.cn/docs/start/install-flash-attention.html
# https://www.aileading.cn/docs/start/install-triton.html
pip install .\bak\flash_attn-2.7.4.post1+cu124torch2.6.0cxx11abiFALSE-cp312-cp312-win_amd64.whl
pip install .\bak\triton-3.2.0-cp312-cp312-win_amd64.whl如果后续在启动过程中 报错,可参考链接中给出的方案升级 gradio
启动
shell
# 启动应用与UI界面
python web_demo.py --flash-attn2 --server-name 127.0.0.1 --server-port 7860 --ui-language=zh --inbrowser --checkpoint-path=Qwen/Qwen2.5-Omni-3B解释下各个参数:
- --flash-attn2:开启 flash-attn2,减少显存使用,加快推理速度
- --server-name 127.0.0.1 --server-port 7860:启动ip和端口
- --ui-language=zh:en - 表示界面是英文版本(默认),zh - 表示是中文版本
- --inbrowser:当服务启动后,是否自动在浏览器打开可视化界面
- --checkpoint-path=Qwen/Qwen2.5-Omni-3B:使用的模型,默认是7B(
Qwen/Qwen2.5-Omni-7B),如果需要使用3B,则配置为3B模型Qwen/Qwen2.5-Omni-3B
使用如上命令启动项目,首次启动时,会从 huggingFace 上下载模型(约23G)。启动后 UI 如下: 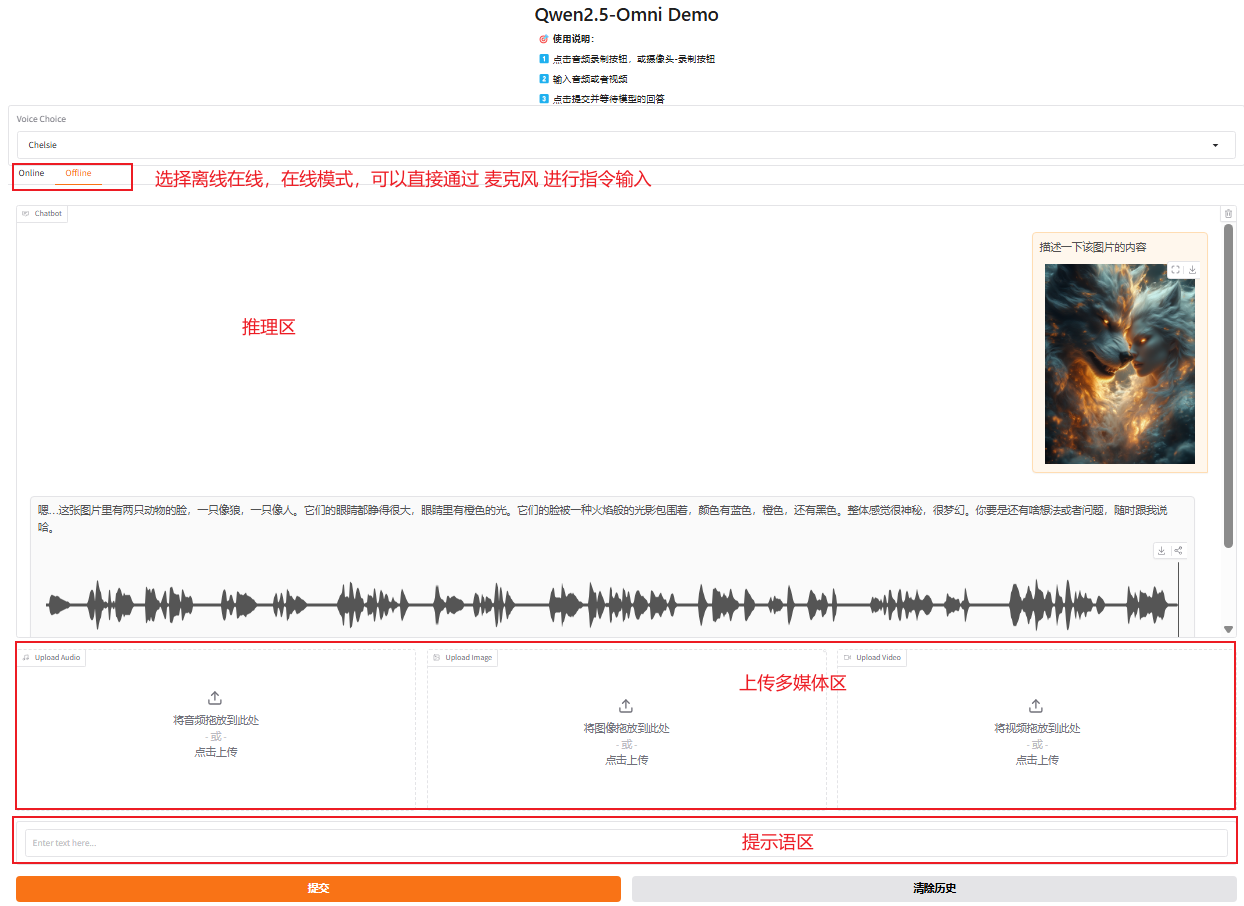
使用
实时交互
离线交互
显存消耗: 
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
