媒体分析与自然语言图像生成插件 Gemini-Flash2.0-Exp
功能介绍
集成了 Google 的 Gemini Flash 2.0 Experimental 模型,可进行:
- 多模式输入支持:
- 文本分析
- 图像分析
- 视频分析
- 音频分析
- 图像生成
安装
- 使用插件管理器安装 ComfyUI-Gemini_Flash_2.0_Exp
- 从 Google AI Studio 获取免费 API 密钥:
- 访问 Google AI Studio
- 使用您的 Google 帐户登录
- 点击“获取 API 密钥”或进入设置
- 创建新的 API 密钥
开始使用
核心节点就如下一个 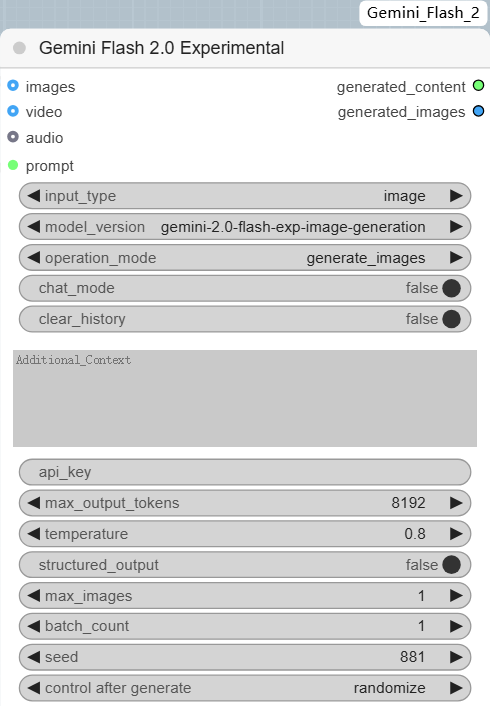
必需输入:
- prompt:用于分析或生成的主文本提示
- input_type:从 [“text”、“image”、“video”、“audio”] 中选择
- model_version:选择模型,目前提供了三种模型
- gemini-2.0-flash-exp:常规多模态模型
- gemini-2.0-flash-thinking-exp-1219:多模态思考模型
- gemini-2.0-flash-exp-image-generation:图片生成模型
- operation_mode:从 [“analysis”、“generate_images”] 中选择
- chat_mode:布尔值,用于启用/禁用聊天功能
- clear_history:布尔值,用于重置聊天历史记录
可选输入:
- text_input:上下文的附加文本输入
- api_key:在 Google AI Studio 中申请的 API 密钥
- images:单图或者多图像输入(多图使用
Batch Images节点将单独拼合) - video:视频帧序列输入
- audio:音频输入
- max_output_tokens:设置最大输出长度(1-8192)
- temperature:控制响应随机性(0.0-1.0)
- structured_output:启用结构化响应格式
- max_images:要处理的最大图像数量(1-16)
- batch_count:要生成的图像数量(用于图像生成模式)
- seed:用于可重现图像生成的随机种子
文本分析
可用于文本摘要总结。

图片分析
可用于图片信息反推。

音频分析
可用于音频转文字;分析音频情感等。

视频分析

分析结果:很准
shell
以下是对视频帧的分析:
**视频内容:**
这段视频似乎是一位穿着中国传统服装(可能是汉服)的年轻女子的特写。她有着精致的外表,精心化妆,包括脸红和口红。她的头发是传统的发髻,装饰着金色发夹和其他装饰元素。背景是坚实的暖黄色。这段视频似乎聚焦于她的面部表情和微妙的动作。
**唇读猜测:**
根据画面上的嘴唇动作,以下是对她可能说的话的一些猜测:
***“你好。”**在某些画面中,她嘴唇的轻微开合可能表示一个简单的问候。
***“谢谢”。**机芯也可能发出“th”或“k”的声音。
***“很漂亮。”**考虑到她的着装背景,她可能是在评论与她的服装或外表有关的事情。
***“我准备好了。”**嘴唇的动作可能会发出“m”的声音。
没有音频或更多上下文,很难确定。然而,这些是基于帧中的视觉线索的一些合理猜测。图像生成
文生图:生成的图片尺寸无法控制,图片生成效果不错。

图生图:(参考生图/局部重绘(去除背景等)/扩图)

文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
