最强视频/数字人生成框架 Wan2.2
官网
通义万相:https://github.com/Wan-Video/Wan2.2
ComfyUI 官方示例:https://docs.comfy.org/zh-CN/tutorials/video/wan/wan2_2
功能介绍
wan2.2 家族包含众多模型,支持文生图/文生视频/图生视频/首尾帧生视频/声音生视频(数字人)/动作复刻功能
文生图/文生视频
输入文本,生成图片和视频(将图片看成是一帧的视频),文生图个人感觉整体不如 Qwen-Image,且中文字体生成的一般,会缺少笔画
图生图/图生视频
首尾帧生视频
声音生视频(数字人)
动作复刻
模型下载
通用模型
- 下载 umt5_xxl_fp8_e4m3fn_scaled.safetensors 并且放到 ComfyUI/models/text_encoders 下
- 下载 wan_2.1_vae.safetensors 并且放到 ComfyUI/models/vae 中
文生图/文生视频
- 下载 wan2.2_t2v_high_noise_14B_fp8_scaled.safetensors 并且放到 ComfyUI/models/diffusion_models 中
- 下载 wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors 并且放到 ComfyUI/models/diffusion_models 中
- (可选)下载加速模型 wan2.2_t2v_lightx2v_4steps_lora_v1.1_high_noise.safetensors 并且放到 ComfyUI/models/loras 中
- (可选)下载加速模型 wan2.2_t2v_lightx2v_4steps_lora_v1.1_low_noise.safetensors 并且放到 ComfyUI/models/loras 中
图生图/图生视频/官方版首尾帧生视频
- 下载 clip_vision_h.safetensors 并且放到 ComfyUI/models/clip_vision 中
- 下载 wan2.2_i2v_high_noise_14B_fp8_scaled.safetensors 并且放到 ComfyUI/models/diffusion_models 中
- 下载 wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors 并且放到 ComfyUI/models/diffusion_models 中
音频生视频
- 下载 wav2vec2_large_english_fp16.safetensors 并且放到 ComfyUI/models/audio_encoders 中
- 下载 wan2.2_s2v_14B_fp8_scaled.safetensors 并且放到 ComfyUI/models/diffusion_models 中
文生图/文生视频工作流
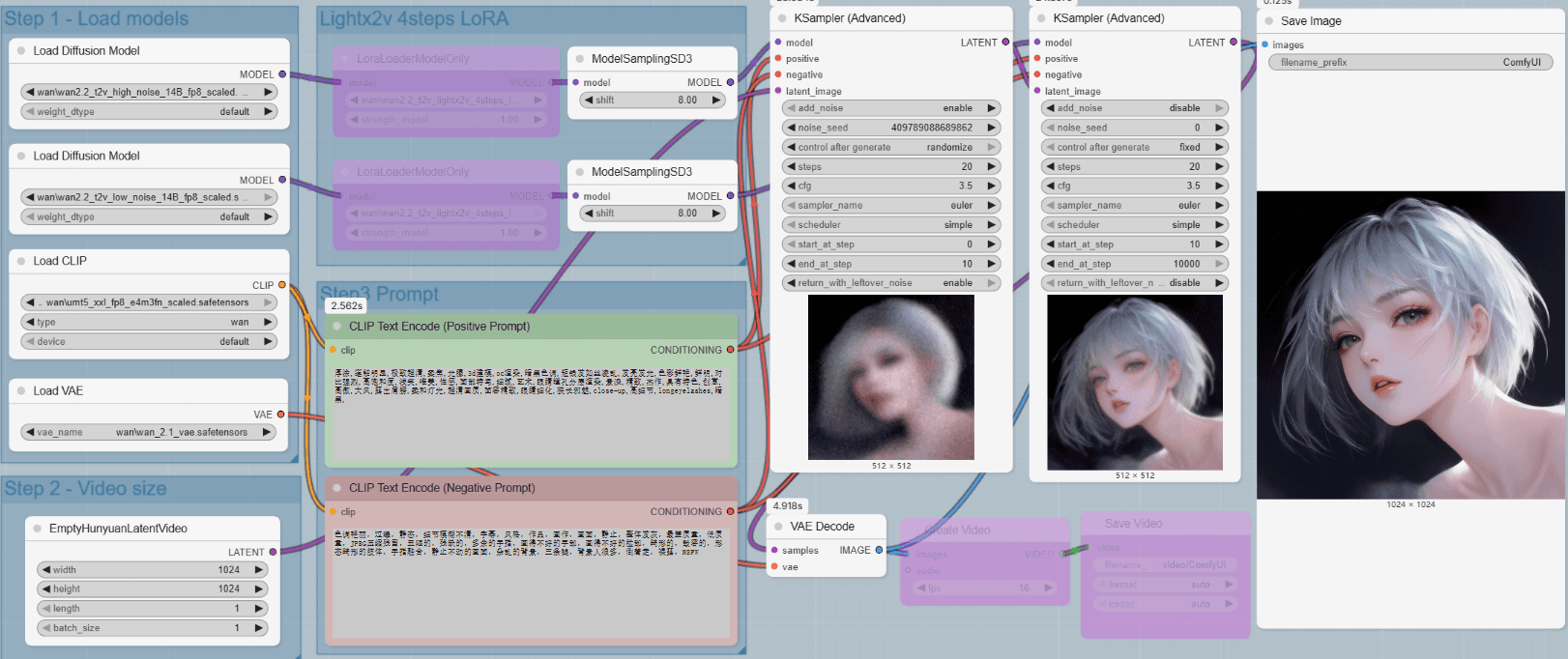
说明:
- 文生图和文生视频用的是同一个工作流(图就是仅生成一帧的视频),所以设置视频帧数为一帧即可
- 4步加速 lora 的引入与否对设置参数有一些影响,引入4步 lora:
- ModelSamplingSD3:shift 5
- steps:4 步长分别是 0-2/2-4
- cfg:1
- 不引入4步 lora:
- ModelSamplingSD3:shift 8
- steps:20 步长分别是 0-10/10-10000
- cfg:3.5
图生视频工作流
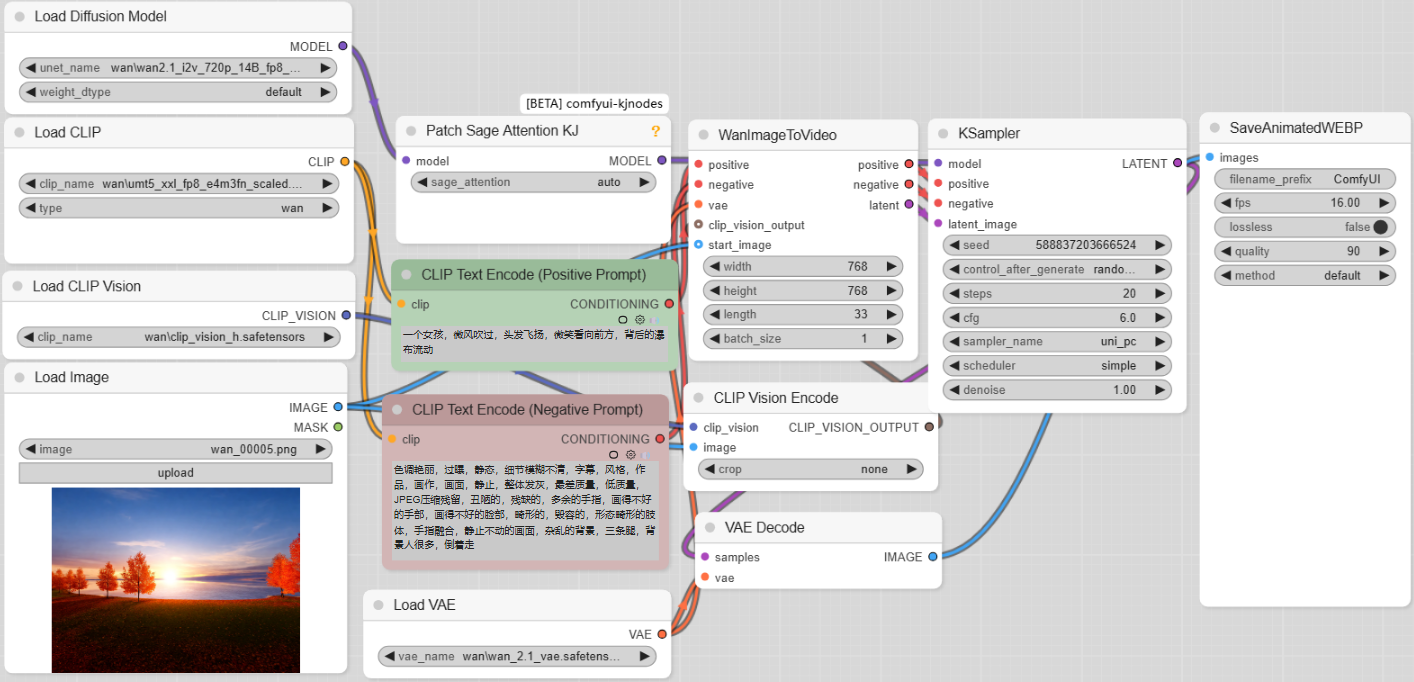
工作流下载地址:百度网盘
注意:Patch Sage Attention KJ 节点是一个推理加速节点,默认选 auto 即可,该节点会在运行时选择最合适的参数。使用该节点需要 安装 sageattention
视频人物替换工作流
显存占用:22G
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
