顶级图像编辑模型 Qwen-Image-Edit
Qwen-Image 官方文档
Qwen-Image-Edit 是 Qwen-Image 的图像编辑版本。它基于20B的Qwen-Image模型进一步训练,成功将Qwen-Image的文本渲染特色能力拓展到编辑任务上,以支持精准的文字编辑。此外,Qwen-Image-Edit将输入图像同时输入到Qwen2.5-VL(获取视觉语义控制)和VAE Encoder(获得视觉外观控制),以同时获得语义/外观双重编辑能力。
模型特性
- 精准文字编辑: Qwen-Image-Edit支持中英双语文字编辑,可以在保留文字大小/字体/风格的前提下,直接编辑图片中文字,进行增删改。
- 语义/外观 双重编辑: Qwen-Image-Edit不仅支持low-level的视觉外观编辑(例如风格迁移,增删改等),也支持high-level的视觉语义编辑(例如IP制作,物体旋转等)
- 强大的跨基准性能表现: 在多个公开基准测试中的评估表明,Qwen-Image-Edit 在编辑任务中均获得SOTA,是一个强大的图像生成基础模型。
模型下载
- text_encoders:文本编码器,下载文件 qwen_2.5_vl_7b_fp8_scaled.safetensors,将其放置到
ComfyUI/models/text_encoders/下 - diffusion_models:扩散模型,下载文件 qwen_image_edit_fp8_e4m3fn.safetensors,将其放置到
ComfyUI/models/diffusion_models/下 - vae:下载文件 qwen_image_vae.safetensors,将其放置到
ComfyUI/models/vae/下 - LoRA 加速模型:Qwen-Image-Lightning-4steps-V2.0.safetensors(2.0相较于1.0,减少了过拟合),放置到
ComfyUI/models/loras/下
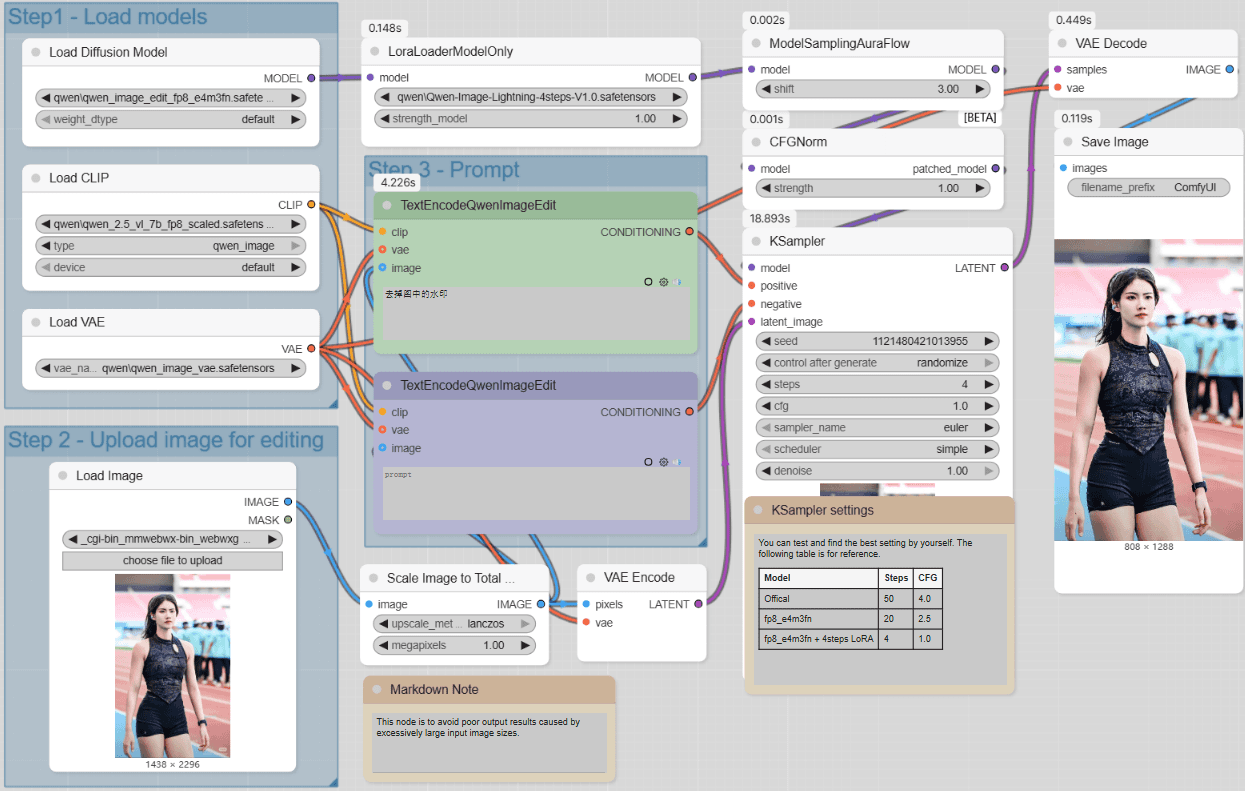
搭建工作流
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
