顶级图像编辑模型 Qwen-Image-Edit-2509
Qwen-Image 官方文档
Qwen-Image-Edit-2509 是 Qwen-Image-Edit 的升级版本。所以除了支持 Qwen-Image-Edit 外的所有特性之外,还做了三个方面的增强。
Qwen-Image-Edit 的介绍见 顶级图像编辑模型 Qwen-Image-Edit
模型特性
Qwen-Image-Edit 核心特性:
- 语义/外观双重编辑: Qwen-Image-Edit 不仅支持 low-level 的
视觉外观编辑(例如风格迁移,增删改等),也支持 high-level 的视觉语义编辑(例如IP制作,物体旋转,人物摆出新的形状等),可用于制作三视图 - 精准文字编辑: Qwen-Image-Edit 支持中英双语文字编辑,可以在保留文字大小/字体/风格的前提下,直接编辑图片中文字,进行增删改。
- 强大的跨基准性能表现: 在多个公开基准测试中的评估表明,Qwen-Image-Edit 在编辑任务中均获得 SOTA,是一个强大的图像生成基础模型。
Qwen-Image-Edit-2509 增强特性:
- 单图一致性增强: 对于单图输入,Qwen-Image-Edit-2509 显著提高了一致性,主要体现在以下方面:
- 人物编辑一致性增强:
增强人脸ID保持,支持各种形象照片、姿势变换; - 商品编辑一致性增强:
增强商品ID保持,支持商品海报编辑; - 文字编辑一致性增强: 除
支持文字内容修改外,还支持多种文字的字体、色彩、材质编辑;
- 人物编辑一致性增强:
- 多图编辑支持: 支持 “人物+人物”,“人物+商品”,“人物+场景” 等多种玩法。
- 原生支持ControlNet: 包括深度图、边缘图、关键点图等
全面测试
下面进行13个场景的测试,左边为原图,右边为编辑后的图。
整体结论:
- 在单个物体的操作方面非常完美(除了三视图的生成);
- 对于字体的生成和编辑趋于完美(部分中英混合场景下会出错,中文的生成与编辑功能强大);
- 对于 ControlNet 图的生成和基于 ControlNet 生图均非常完美;
- 多张图片场景下:人人合照不完美(部分人物ID保持不足,即脸部不像);人景合照以及人品合照比较完美。
具体例子如下:
物体删除

prompt: 去除水印
效果:观察图片右下角的水印,去除的很完美。
物体修改

prompt:将女孩的衣服换成运动背心,牛仔裤
效果:完美。
物体新增

prompt:女孩的左腹部添加玫瑰花形状的纹身
效果:完美。
物体三视图生成(物体旋转)

prompt:获得后视图,保持人物的姿势
效果:一般,无法保持原本的姿势下获得旋转视图。
风格转换
动漫转真人(仅使用 qwen-image-edit-2509 模型)  动漫转真人(增加 qwen-anime-to-realistic lora)
动漫转真人(增加 qwen-anime-to-realistic lora) 
prompt:转变成真实人物风格
真人转动漫 
prompt:转变成Chibi风格
效果:增加 lora 后,动漫转真人效果完美;真人转动漫效果完美(不过尝试转换成韩漫风格失败)。
语义编辑
语义编辑:在保持原始图像视觉语义不变的前提下,对图像内容进行修改。

prompt:女孩两只手摆出一个爱心的形状
效果:完美。可用于表情包制作。
双人合照

prompt:两个人愉快的合照
效果:一般,人物的ID保持性不是很优秀,比如没保持住高圆圆的脸部特征。(去官网测试也是如此)
人景合照

prompt:image1中的人物站在image2的花丛前
效果:完美。
人品合照

prompt:image1中的人物戴上image2女孩的项链
效果:完美(给出的品并不完整,AI 还脑补了半个项链)。
获取图片的 ControlNet 图片

prompt:获取图中女孩的深度图
效果:完美。(canny/openpose 等也是同样操作)
原生支持 controlNet 生图

prompt:获取图中女孩的深度图
效果:完美。(canny/openpose 等也是同样操作)
文字生成

prompt:将女孩的衣服换成纯白色,上衣胸部写着“qwen不错”
效果:部分完美。(中文完美,英文出错,使用官网生成也出错)
文字编辑(字体/色彩/材质修改)

prompt:将“不错”两个字改为银色,行书,金属材质
效果:完美。
模型下载
- text_encoders:文本编码器,下载文件 qwen_2.5_vl_7b_fp8_scaled.safetensors,将其放置到
ComfyUI/models/text_encoders/下 - diffusion_models:扩散模型,下载文件 qwen_image_edit_2509_fp8_e4m3fn.safetensors,将其放置到
ComfyUI/models/diffusion_models/下 - vae:下载文件 qwen_image_vae.safetensors,将其放置到
ComfyUI/models/vae/下 - LoRA 加速模型:Qwen-Image-Lightning-8steps-V2.0.safetensors(2.0相较于1.0,减少了过拟合),放置到
ComfyUI/models/loras/下
搭建工作流
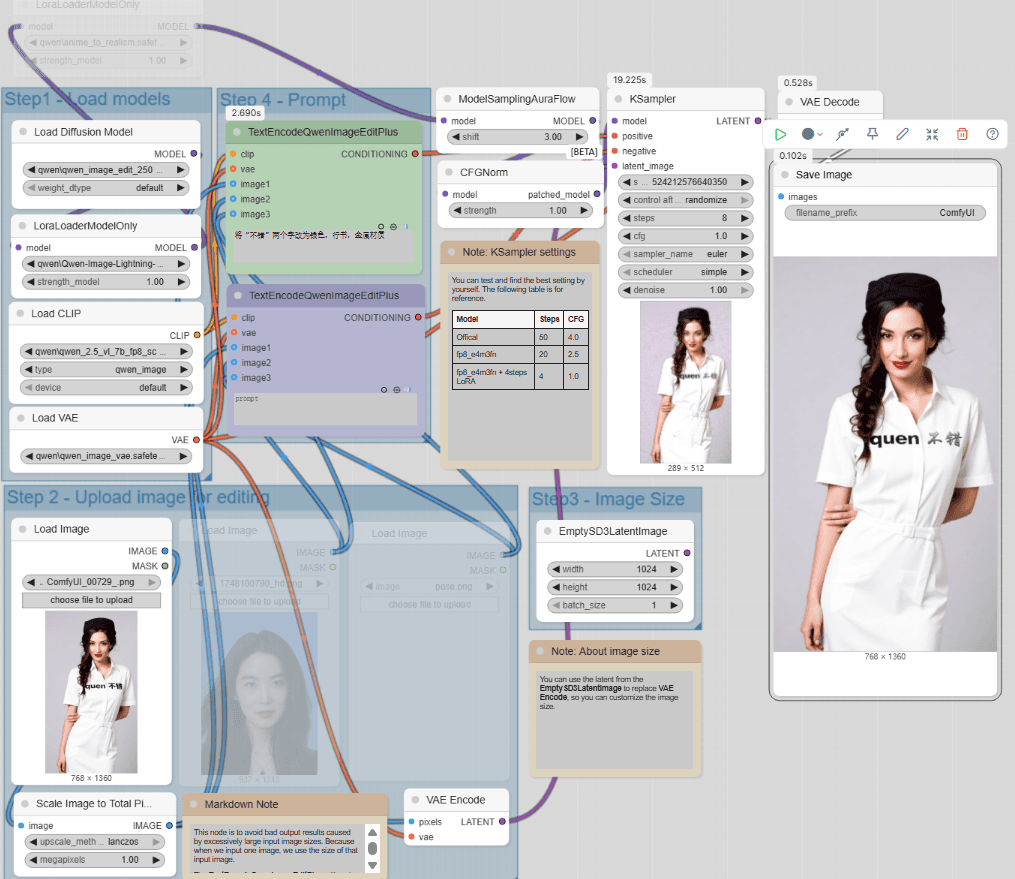
说明:
- 显存占用:22G
- 生图的图片尺寸默认使用第一张图片的尺寸,当然第一张图片如果尺寸太大的话,工作流会做切割;如果想自定义图片大小,请将
EmptySD3LatentImage节点替换掉VAE Encode节点后,接入采样器
文章的最后,如果您觉得本文对您有用,请打赏一杯咖啡!感谢!
